Replicação serverless: uso de funções lambda para sincronização de dados

Mesmo em sistemas pequenos, entender a importância de backups (cópias de segurança) em bancos de dados é essencial para metrificar a maturidade de um projeto.
Dentro de um fluxo de sincronização de informações entre bancos de dados, pode-se citar como ponto focal um serviço em específico: a replicação. Esse processo consiste na cópia de dados do banco pai para o filho.
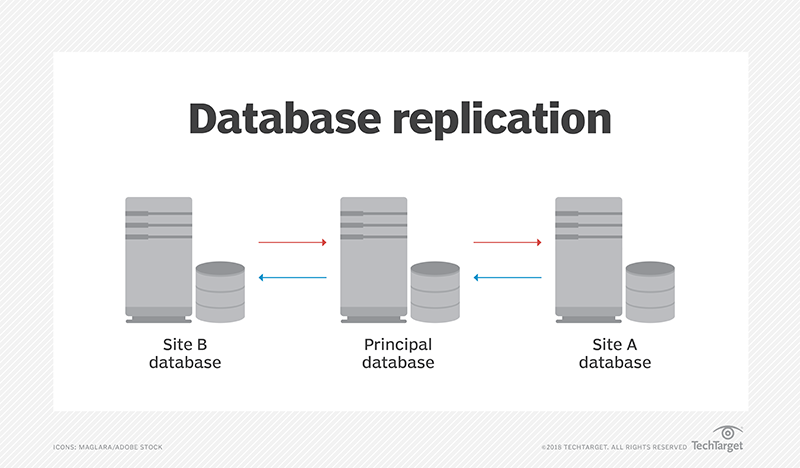
Para tanto, construir um serviço de replicação flexível e escalável é peça chave para a segurança e qualidade de projetos.
Serverless functions
Serverless functions são pequenos blocos de código que rodam sob demanda em ambientes de nuvem, sem que precisemos nos preocupar com a criação, manutenção ou escalabilidade de servidores.
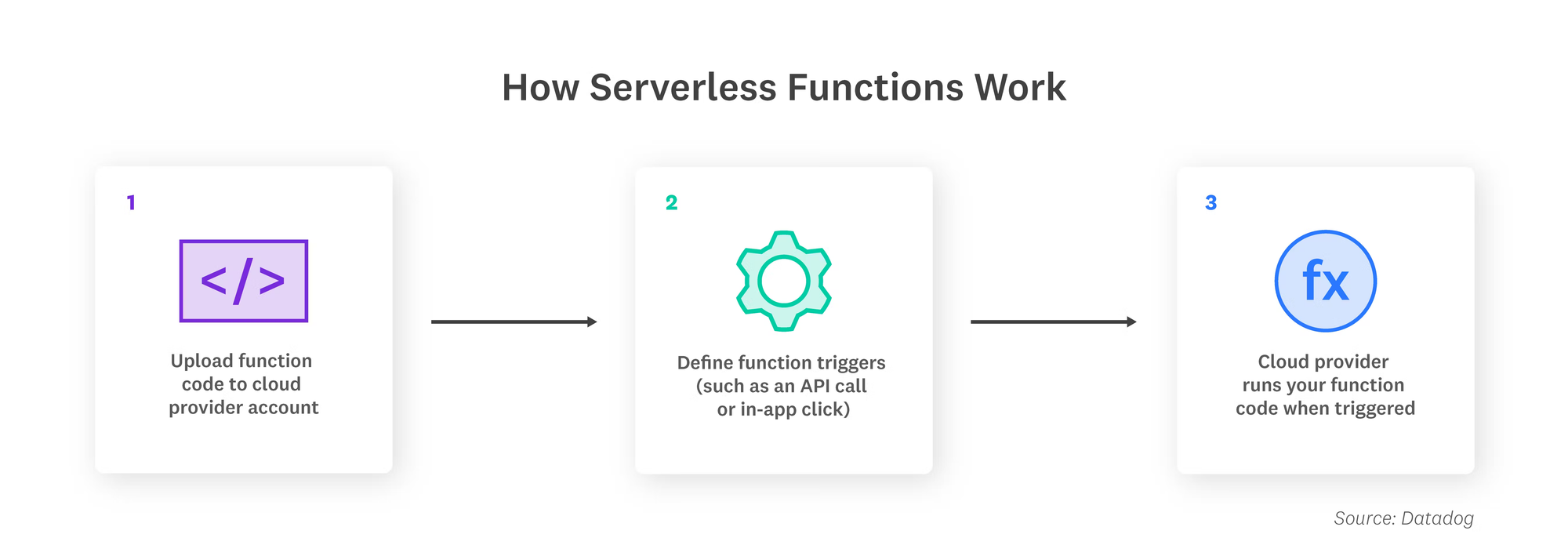
Na prática, você escreve apenas a lógica da função e a provê em uma plataforma (como AWS Lambda, Google Cloud Functions, Azure Functions ou Appwrite Functions). A nuvem se encarrega de provisionar recursos e, dependendo da plataforma, escalar automaticamente.
Dentre as qualidades desse modelo de execução, podemos citar:
- Custo eficiente
- Como a função só gasta quando é executada, não precisamos lidar com o custo de manter uma ociosidade
- Isolamento e modularidade
- Cada função é independente, facilitando a construção de arquiteturas orientadas a microserviços.
Por esses motivos, essa ferramenta será o alicerce que sustentará a lógica por trás do serviço de replicação.
Implementação
Como podemos usar serverless functions em um contexto de produção?
Caso de uso
Pensaremos na seguinte situação:
Tenho um sistema consumido por cerca de 100 usuários e que, em média, recebe 1000 requisições POST por dia. Para armazenar esses dados, há um banco de dados em uma VPS na Carolina do Norte, EUA.
Quando pensamos em estabilidade, automaticamente lembramos de serviços em nuvem. Contudo, mesmo que sua segurança seja sim superior, não é interessante apostarmos todas nossas fichas em apenas um jogo.
Por exemplo, caso haja um ataque hacker no datacenter que acomoda a máquina na qual está o nosso banco, o sistema ficaria inutilizável.
Por isso, distribuiremos cópias de segurança desse banco.
Tecnologias
Felizmente, possuímos um oceano de possiblidades quando pensamos nas tecnologias. Nós da ATLA ITC, recomendamos as seguintes:
- Banco de dados: MongoDB, PostgreSQL, MySQL
- Plataforma para as serverless functions: Appwrite e AWS
- Bucket para processamento: Appwrite, MinIO, S3
- Linguagens: Python, Javascript, PHP, Ruby
Arquitetura e Diagrama
Um ótimo padrão de arquitetura para projetos com essas características é o manager/worker. Como o processo de migração dos dados demanda muito poder computacional, não é interessante manter todo esse custo para uma única função. Por isso, seguimos esse modelo.
Usando o ecossistema do Appwrite, diagramamos as seguintes interações:
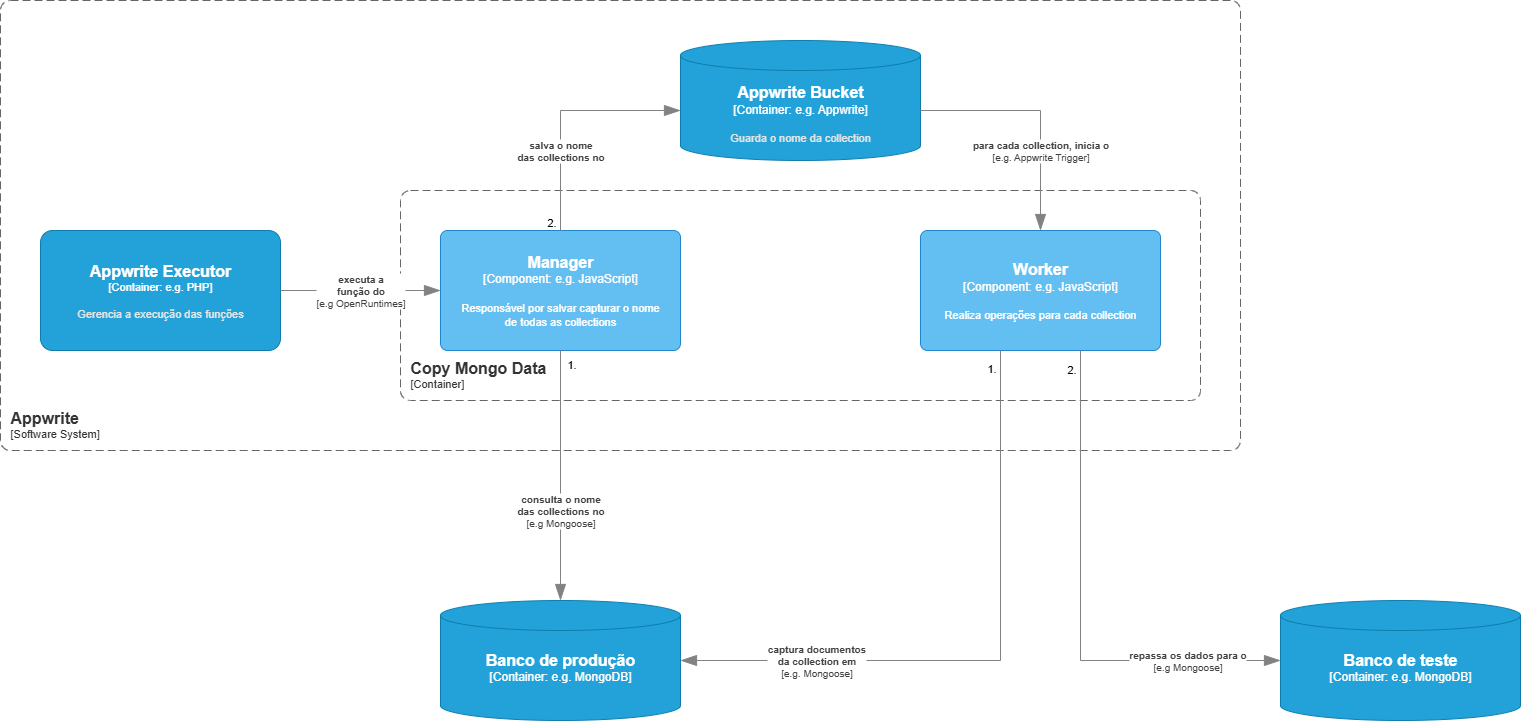
A partir desses relacionamentos, é totalmente possível construir um serviço totalmente funcional.
Conclusão
Análise panorâmica dos resultados
A soma de replicação de dados com serverless functions cria uma fundação sólida para projetos que exigem segurança, escalabilidade e baixo custo.
Ao distribuir cópias de segurança e utilizar funções sob demanda, conseguimos manter a integridade das informações mesmo em cenários de falha crítica.
Essa arquitetura, baseada em manager/worker e apoiada por plataformas modernas como Appwrite e AWS Lambda, garante um equilíbrio ideal entre robustez e simplicidade operacional.
Em resumo, não apenas reduzimos riscos de indisponibilidade, mas também elevamos a maturidade do projeto, transformando o backup e a replicação em pilares estratégicos da infraestrutura.